
Session 概念
session 为会话的意思,普通的requests.get请求方式只适用于单次请求,而无法多次来回请求数据。
用法介绍
如下,是一个用于登录的例子
session = requests.session() # 设置一个会话
resp = session.post(url, data=data) #通过这个会话来发送post请求,包含一个数据
print(resp.cookie) # 打印得到的Cookie数据
print(resp.text) # 打印请求到的代码数据
Cookie 登录 17K 小说网
import requests
url = "https://passport.17k.com/ck/user/login" #发送Post请求登录的url
bookshelf = "https://user.17k.com/ck/author/shelf?page=1&appKey=2406394919" #目标数据地址,实为书架数据
session = requests.session() #打开一个会话
data = {
"loginName": "13473197850",
"password": "dong0305" #设置用户名密码
}
#方法一:通过上面data里面的用户名和密码发送请求,然后再通过这个会话去请求书架的地址
#resp = session.post(url, data=data) #实现登录
#resp_books = session.get(bookshelf)
#print(resp_books.json()) #以json形式输出
#方法二:直接通过headers设置cookie实现获取该用户的数据,省去了登录过程但是需要Cookie
resp_books = session.get(bookshelf, headers={
"Cookie": "GUID=f6d369f7-5e48-4028-ad42-85afcda4bafd; c_referer_17k=https://www.google.com/; Hm_lvt_9793f42b498361373512340937deb2a0=1624549433; c_channel=0; c_csc=web; accessToken=avatarUrl%3Dhttps%253A%252F%252Fcdn.static.17k.com%252Fuser%252Favatar%252F02%252F62%252F96%252F77819662.jpg-88x88%253Fv%253D1624549512000%26id%3D77819662%26nickname%3D%25E8%25BE%25A3%25E7%2599%25BD%25E8%258F%259CLee%26e%3D1640103111%26s%3D498c6b1ec235472a; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%2277819662%22%2C%22%24device_id%22%3A%2217a3eb0cf5f7a6-0bfbff5fe7e464-34647600-2073600-17a3eb0cf60b28%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E8%87%AA%E7%84%B6%E6%90%9C%E7%B4%A2%E6%B5%81%E9%87%8F%22%2C%22%24latest_referrer%22%3A%22https%3A%2F%2Fwww.google.com%2F%22%2C%22%24latest_referrer_host%22%3A%22www.google.com%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC%22%7D%2C%22first_id%22%3A%22f6d369f7-5e48-4028-ad42-85afcda4bafd%22%7D; Hm_lpvt_9793f42b498361373512340937deb2a0=1624551118"
})
print(resp_books.json())
抓取梨视频,解决防盗链问题
简介
防盗链包含在页面的请求头中,关键字为 Referer
原理是溯源,即校验此页面的上一个页面是否为预设值。
处理时只需要将 "Referer": url 放入 headers 即可。
实例
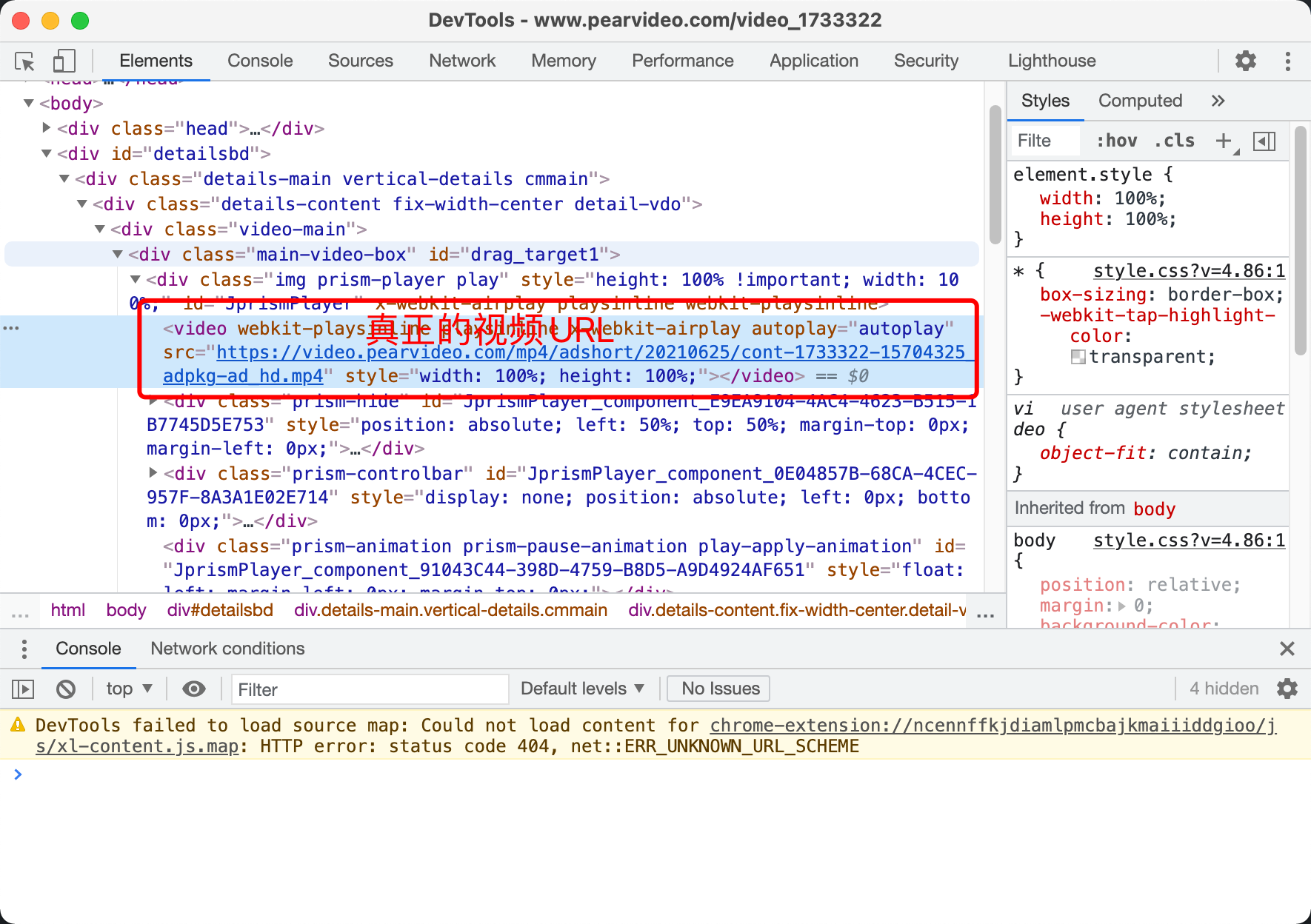
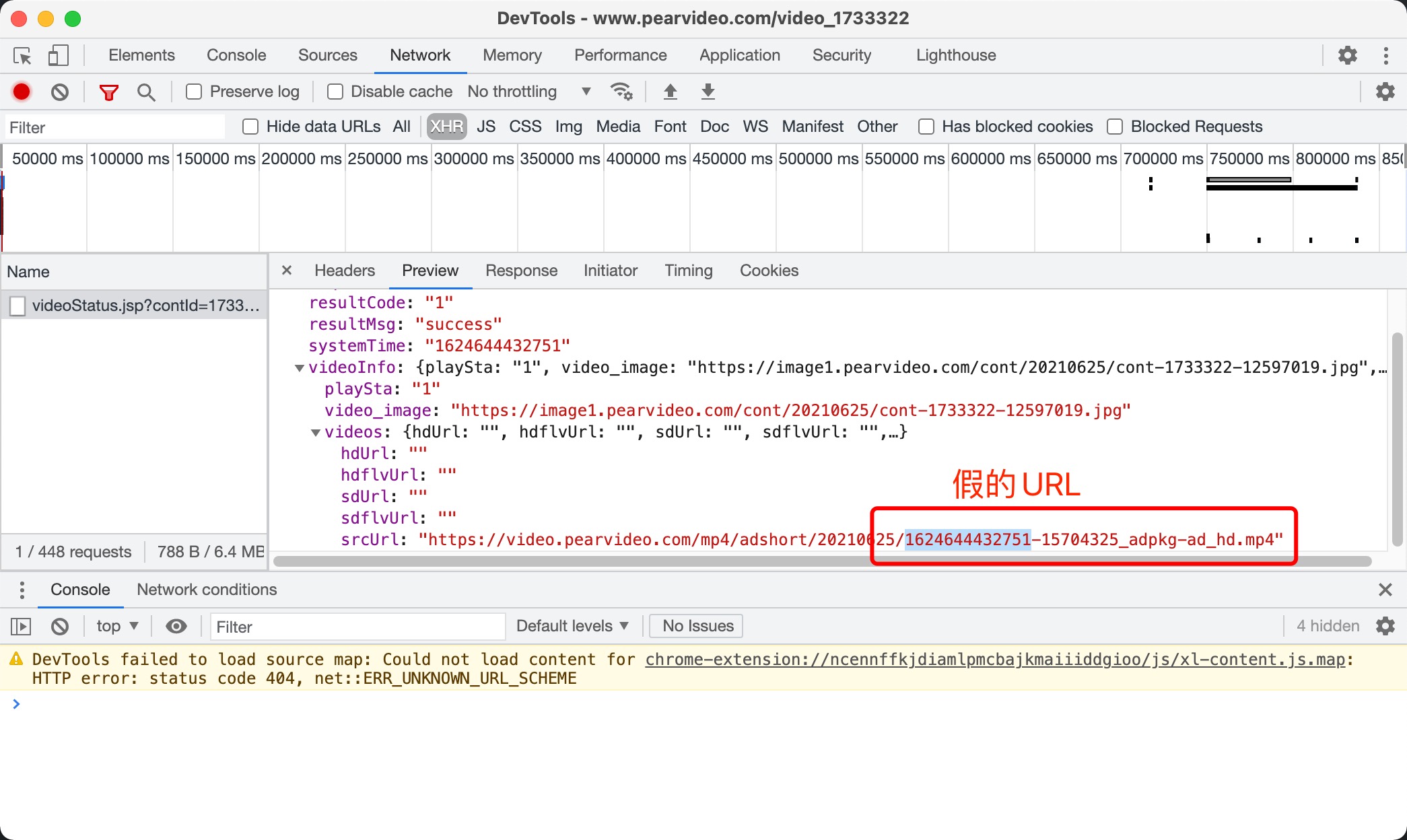
本例子为抓取梨视频的视频文件,比较复杂,视频播放页源代码中未直接包含视频 url,用到了二次请求,视频文件的 url 也与通过网页获取到的视频文件 url 不符,需要做一些处理,如下图:
from os import write
import requests
url = "https://www.pearvideo.com/video_1733239" #视频播放页面
contid = url.split("_")[1] #取到视频的contId
videoState = f"https://www.pearvideo.com/videoStatus.jsp?contId={contid}&mrd=0.791747833440223" #将contId插入到二次请求的url地址中
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36",
"Referer": url #防盗链处理
}
resp = requests.get(videoState, headers=headers) #请求二次请求的url
dic = resp.json() #设置一个字典
srcurl = dic['videoInfo']['videos']['srcUrl'] #这个是假的视频url
systemtime = dic['systemTime'] #另外一个校验的参数
srcurl = srcurl.replace(systemtime, f"cont-{contid}") #将contId替换掉假的url中假的部分,得到真正的url
with open(f"{contid}.mp4", mode="wb") as f: #保存文件
f.write(requests.get(srcurl).content)