
(JS)基于协同过滤算法的商品推荐系统设计与实现(UserCF)
前言
最近接了一个本科毕业设计,题目是“基于个性化推荐的购物商城小程序设计与开发”。导师要求使用NodeJS做后端,使用协同过滤算法实现个性化推荐,鉴于第一次接触并且也实现了效果,特此记录一下。
这里我使用的相似度计算方法是Pearson相关系数,基于用户进行协同过滤(即UserCF)。
每个商品都会手工贴上很多标签,也就是这个商品的属性,在得到用户可能感兴趣的标签列表之后从这些标签下随机筛选商品做为推荐列表返回给前端。
工作流程
- 用户点击商品详情页
- 点击行为记录到数据库(tag_count表该对应的标签count+1)
- 系统检索该用户点击过的所有标签,获取每个用户对这些标签的点击数据,得到每个用户在该用户点击过的标签下的兴趣向量,分别对其应用Pearson相关系数进行相似度的计算
- 用户相似度从高到低排列,给出N个用户未点击过的新标签
- 从这些标签中筛选N个商品,同时从该用户点击量比较高的标签中筛选一些商品作为推荐列表返回给用户(比例2:1);如果是新用户,没有点击标签数据和用户相似度数据则从商品库中随机筛选商品。
算法详细流程
现假设用户A为被推荐用户,用户B为对比用户。
用户A点击了某商品的详情页,该商品的标签为:华为、5G、手机,此时系统先把tag_count表中,userId为用户A、tagName是华为或5G或手机的count+1(记录用户行为)。
然后需要更新用户相似度。
首先系统从tag_count表中去检索用户A点击过的所有标签,得到用户A对他访问过的所有标签的原始兴趣向量,数据如下:
[
{
name: "华为", // 标签的名称
count: 30 // 该用户访问该标签下商品的次数
},{
name: "5G",
count: 15
},
...
]
然后需要对该兴趣向量数组进行零均值化(Zero-centered,就是每个标签的count减去count的平均值),得到最终用于相似度计算的兴趣向量。
此时,系统再从tag_count表中检索其他用户点击过的所有标签和这些标签的点击次数,得到与上面数据结构一样的其他用户的兴趣向量并将其零均值化(与计算用户A兴趣向量的操作一致)。
然后就可以分别开始计算用户A与其他用户的相似度了,此时相似度计算方法就是Cosine余弦相似度(Pearson相关系数就是对向量零均值化后应用余弦相似度)。
计算步骤如下:
对用户A与用户B各自的兴趣向量取交集(重合部分),得到如下两个数组:

求用户A与用户B的兴趣向量的内积作为分子(点乘,就是a1b1+a2b2+…+an*bn):
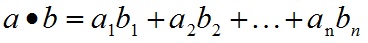
求用户A与用户B的兴趣向量各自的模数的乘积作为分母:
$$
\sqrt{ a_1^2+a_2^2+…+a_n^2} \times \sqrt{ b_1^2+b_2^2+…+b_n^2}
$$最后让内积/各自的模数的乘积得出结果即为用户A与用户B的相似度。
用户B点击过的其他标签,就是用户A可能也比较感兴趣的标签,与用户A相似度最高的用户点击过的标签,就是最值得推荐给用户A的标签。
计算公式如下: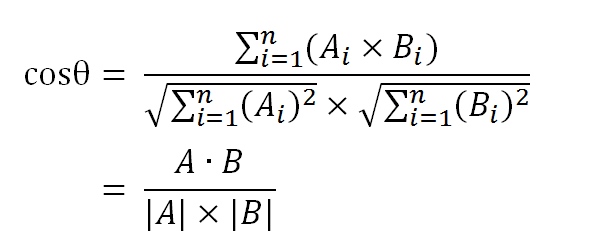
得到用户A与用户B的相似度数值,以及用户B点击过的其他标签,作为一条记录更新或插入到user_similarity表中:
| id | user_a | user_b | similarity | taglist |
|---|---|---|---|---|
| 1 | 00001 | 00002 | 0.67616 | 生鲜,牛仔裤,三星 |
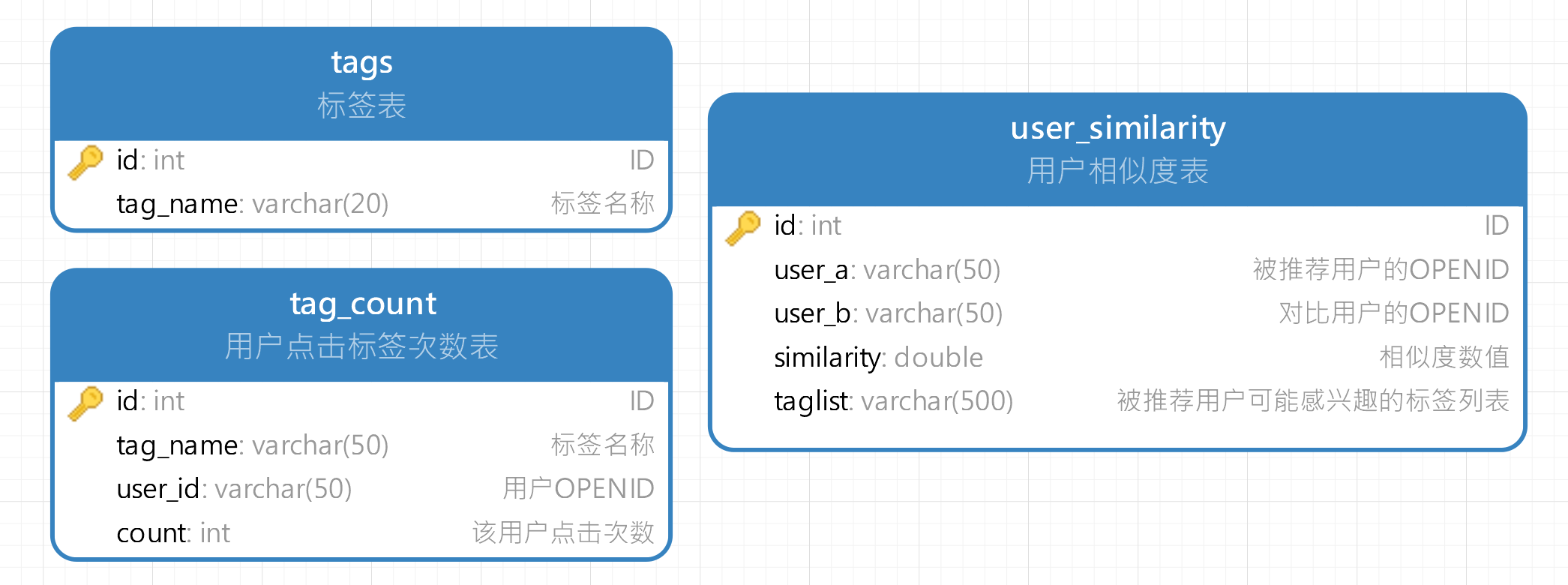
数据库设计
代码实现
// 相似度算法部分:
async function updateUserSimilarity(uid) {
const targetUserVector = await getInterestVectorByUser(uid) //目标用户平均后的兴趣向量
const relateTagList = targetUserVector.map(el => el.name) //相关标签列表
const otherUserVectors = {} // 其他用户的兴趣向量
let userSimilarityList = []
// 获取其他用户在该用户向量的相关标签下的兴趣向量
query(`select * from tag_count where user_id != "${uid}"`, async (res) => {
if (!res.length) return
for (let el of res) {
// 构建其他用户的兴趣向量列表,存储为对象形式,键就是用户的OPENID,值为该用户兴趣向量
// 如果对应用户下没有数组,则将其初始化为数组形式
if (typeof otherUserVectors[el.user_id] !== "object") otherUserVectors[el.user_id] = []
// 将点击量数据追加进对应用户的兴趣向量数组
otherUserVectors[el.user_id].push({ tag_name: el.tag_name, count: el.count })
}
// 开始计算每一个用户对于目标用户的相似度
for (let user in otherUserVectors) {
// 将用户的原始兴趣向量数组转换为零均值化后的兴趣向量数组
otherUserVectors[user] = calculateAverageVector(otherUserVectors[user])
// 计算相似度,并获取到目标用户可能感兴趣的新标签列表,最后构建成相似度列表userSimilarityList
userSimilarityList.push({
user,
similarity: calculateSimilarity(uid, user, targetUserVector, otherUserVectors[user], relateTagList), // 用户相似度
tagList: getRecommendTag(relateTagList, otherUserVectors[user]) // 推荐标签
})
}
// 将用户相似度数据写入数据库,用于生成推荐商品列表
updateSimilarityDB(userSimilarityList, uid)
})
}
/**
* 获取指定用户的兴趣向量
*
* @param {uid} String 指定用户ID
*/
async function getInterestVectorByUser(uid) {
// 获取该用户对所有标签的点击次数
let tagCount = [];
await query(`select * from tag_count where user_id="${uid}"`, async (res) => {
if (!res.length) return
tagCount = calculateAverageVector(res)
})
return tagCount
}
/**
* 给定一个向量数组,计算平均值,然后令向量-平均值得到新数组后返回
*
* @param {origin} Object[] 原始向量数组
*/
function calculateAverageVector(origin) {
let tagCountSum = 0, tagCountAvg = 0;
const tagCount = []
for (let el of origin) {
tagCountSum += el.count
tagCount.push({ name: el.tag_name, count: el.count })
}
tagCountAvg = tagCountSum / tagCount.length
for (let el of tagCount) {
el.count -= tagCountAvg
}
return tagCount
}
/**
* 计算两个用户的余弦相似度
*
* @param {user_a} String 用户A的Open-ID
* @param {user_b} String 用户B的Open-ID
* @param {a_vector} Object[] 用户A的兴趣向量
* @param {b_vector} Object[] 用户A的兴趣向量
* @param {relateTagList} String[] 相关标签列表
*/
function calculateSimilarity(user_a, user_b, a_vector, b_vector, relateTagList) {
// vectorInnerProduct:向量AB的内积
// vectorProductA,vectorProductB为向量AB的模数
let vectorInnerProduct = 0, vectorProductA = 0, vectorProductB = 0
for (let tag of relateTagList) {
const a_select = a_vector.find(el => el.name === tag), // 取交集
b_select = b_vector.find(el => el.name === tag)
if (a_select && b_select) {
vectorInnerProduct += a_select.count * b_select.count; // 内积累加
vectorProductA += a_select.count * a_select.count; // 模数累加
vectorProductB += b_select.count * b_select.count;
}
}
vectorProductA = Math.sqrt(vectorProductA) // 开根号
vectorProductB = Math.sqrt(vectorProductB)
return vectorInnerProduct / (vectorProductA * vectorProductB) // 余弦相似度计算的最后一步:内积/向量模数乘积
}
// 根据原有的标签列表 和 其他用户的兴趣向量,获取用户可能感兴趣的新标签列表
function getRecommendTag(relateTagList, userVector) {
const vectorList = userVector.filter(el => {
return !relateTagList.includes(el.name)
})
return vectorList.map(el => el.name)
}
// 更新用户相似度数据库
function updateSimilarityDB(list, uid) {
console.log(list);
for (let el of list) {
if (el.similarity === NaN || el.user === 'undefined') continue // 存在错误数据,跳过写入
query(`select * from user_similarity where user_a="${uid}" and user_b="${el.user}"`, (e) => {
if (e.length) {
// 如果已经存在记录则对其记录进行更新,将标签列表以逗号进行拼接存入varchar类型的taglist字段
query(`update user_similarity set similarity=${el.similarity.toFixed(5)},taglist="${el.tagList.join(",")}" where user_a="${uid}" and user_b="${el.user}"`
, (res) => { })
} else {
// 如果不存在记录就插入一条新记录
query(`insert into user_similarity(user_a,user_b,similarity,taglist) values("${uid}","${el.user}",${el.similarity.toFixed(5)},"${el.tagList.join(",")}")`
, (res) => { })
}
})
}
}